1 Binary Systems
1.1 Digital Computers and Digital Systems
Digital computers have made possible many scientific, industrial, and commercial advances that would have been unattainable otherwise. Our space program would have been impossible without real-time, continuous computer monitoring, and many business enterprises function efficiently only with the aid of automatic data processing. Computers are used in scientific calculations, commercial and business data processing, air traffic control, space guidance, the educational field, and many other areas. The most striking property of a digital computer is its generality; it can follow a sequence of instructions, called a program that operates on given data. The user can specify and change programs and/or data according to the specific need. As a result of this flexibility, general-purpose digital computers can perform a wide variety of information-processing tasks.
The general-purpose digital computer is the best-known example of a digital system. Other examples include telephone switching exchanges, digital voltmeters, digital counters, electronic calculators, and digital displays. Characteristic of a digital system is its manipulation of discrete elements of information. Such discrete elements may be electric impulses, the decimal digits, the letters of an alphabet, arithmetic operations, punctuation marks, or any other set of meaningful symbols. The juxtaposition of discrete elements of information represents a quantity of information. For example, the letters d, o, and g form the word dog. The digits 237 form a number. Thus, a sequence of discrete elements forms a language, that is, a discipline that conveys information. Early digital computers were used mostly for numerical computations. In this case, the discrete elements used are the digits. From this application, the term digital computer has emerged. A more appropriate name for a digital computer would be a “discrete information-processing system.”
Discrete elements of information are represented in a digital system by physical quantities called signals. Electrical signals such as voltages and currents are the most common. The signals in all present-day electronic digital systems have only two discrete values and are said to be binary. The digital-system designer is restricted to the use of binary signals because of the lower reliability of many-valued electronic circuits. In other words, a circuit with ten states, using one discrete voltage value for each state, can be designed, but it would possess a very low reliability of operation. In contrast, a transistor circuit that is either on or off has two possible signal values and can be constructed to be extremely reliable. Because of this physical restriction of components, and because human logic tends to be binary, digital systems that are constrained to take discrete values are further constrained to take binary values.
Discrete quantities of information arise either from the nature of the process or may be quantized from a continuous process. For example, a payroll schedule is an inherently discrete process that contains employee names, social security numbers, weekly salaries, income taxes, etc. An employee’s paycheck is processed using discrete data values such as letters of the alphabet (names), digits (salary), and special symbols such as $. On the other hand, a research scientist may observe continuous process but record only specific quantities in tabular form. The scientist is thus quantizing his continuous data. Each number in his table is a discrete element of information.
Many physical systems can be described mathematically by differential equations whose solutions as a function of time give the complete mathematical behavior of the process. An analog computer performs a direct simulation of a physical system. Each section of the computer is the analog of some particular portion of the process under study. The variables in the analog computer are represented by continuous signals, usually electric voltages that vary with time. The signal variables are considered analogous to those of the process and behave in the same manner. Thus, measurements of the analog voltage can be substituted for variables of the process. The term analog signal is sometimes substituted for continuous signal because “analog computer” has come to mean a computer that manipulates continuous variables.
To simulate a physical process in a digital computer, the quantities must be quantized. When the variables of the process are presented by real-time continuous signals, the latter are quantized by an analog-to-digital conversion device. A physical system whose behavior is described by mathematical equations is simulated in a digital computer by means of numerical methods. When the problem to be processed is inherently discrete, as in commercial applications, the digital computer manipulates the variables in their natural form.
The memory unit of a digital computer stores programs as well as input, output, and intermediate data. The processor unit performs arithmetic and other data-processing tasks as specified by a program. The control unit supervises the flow of information between the various units. The control unit retrieves the instructions, one by one, from the program that is stored in memory. For each instruction, the control unit informs the processor to execute the operation specified by the instruction. Both program and data are stored in memory. The control unit supervises the program instructions, and the processor manipulates the data as specified by the program.
The program and data prepared by the user are transferred into the memory unit by means of an input device such as a keyboard. An output device, such as a printer, receives the result of the computations and the printed results are presented to the user. The input and output devices are special digital systems driven by electromechanical parts and controlled by electronic digital circuits.
An electronic calculator is a digital system similar to a digital computer, with the input device being a keyboard and the output device a numerical display. Instructions are entered in the calculator by means of the function keys, such as plus and minus. Data are entered through the numeric keys. Results are displayed directly in numeric form. Some calculators come close to resembling a digital computer by having printing capabilities and programmable facilities. A digital computer, however, is a more powerful device than a calculator. A digital computer can accommodate many other input and output devices; it can perform not only arithmetic computations, but logical operations as well and can be programmed to make decisions based on internal and external conditions.
It has already been mentioned that a digital computer manipulates discrete elements of information and that these elements are represented in the binary form. Operands used for calculations may be expressed in the binary number system. Other discrete elements, including the decimal digits, are represented in binary codes. Data processing is carried out by means of binary logic elements using binary signals. Quantities are stored in binary storage elements.
1.1.1 Applications and types of microprocessors
Today, microprocessors are found in two major application areas:
• Computer system applications
• Embedded system applications
Embedded systems are often high-volume applications for which manufacturing cost is a key factor. More and more embedded systems are mobile battery-operated systems. For such systems power consumption (battery time) and size are also critical factors. Because they are specifically designed to support a single application, embedded systems only integrate the hardware required to support this application. They often have simpler architectures than computer systems. On the other hand, they often have to perform operations with timings that are much more critical than in computer systems.
A cellular phone for instance must compress the speech in real time; otherwise, the process will produce audible noise. They must also perform with very high reliability. A software crash would be unacceptable in an ABS brake application. Digital Signal Processing applications are often viewed as a third category of microprocessor applications because they use specialized CPUs called DSPs. However, in reality they qualify as specialized embedded applications.
Today, there are 3 different types of microprocessors optimized to be used in each application area:
• Computer systems: General-purpose microprocessors.
• Embedded applications: Microcontrollers
• Signal processing applications: Digital Signal Processors (DSPs)
In reality, the boundaries of application areas are not as well defined as they seem. For instance, DSPs can be used in applications requiring a high computational speed, but not necessarily related to signal processing. Such applications include computer video boards and specialized co-processor boards designed for intensive scientific computation. On the other hand, powerful general-purpose microprocessors are used in high-end digital signal processing equipment designed for algorithm development and rapid prototyping. The following sections list the typical features and application areas for the three types of microprocessors.
General purpose microprocessors
Applications: Computer systems
Manufacturers and models: Intel-Pentium, Motorola-PowerPC, Digital-Alpha Chip, LSI Logic-SPARC family (SUN), ... etc.
Typical features
• Wide address bus allowing the management of large memory spaces
• Integrated hardware memory management unit
• Wide data formats (32 bits or more)
• Integrated co-processor, or Arithmetic Logic Unit supporting complex numerical
operations, such as floating point multiplications.
• Sophisticated addressing modes to efficiently support high-level language functions.
• Large silicon area
• High cost
• High power consumption
Embedded systems: Microcontrollers
Application examples: Television set, wristwatches, TV/VCR remote control, home appliances, musical cards, electronic fuel injection, ABS brakes, hard disk drive, computer mouse / keyboard, USB controller, computer printer, photocopy machine, ... etc.
Manufacturers and models: Motorola-68HC11, Intel-8751, Microchip-PIC16/17family, Cypress-PsoC family, … etc.
Typical features
• Memory and peripherals integrated on the chip
• Narrow address bus allowing only limited amounts of memory.
• Narrow data formats (8 bits or 16 bits typical)
• No coprocessor, limited Arithmetic-Logic Unit.
• Limited addressing modes (High-level language programming is often inefficient)
• Small silicon area
• Low cost
• Low power consumption.
Signal processing: DSPs
Application examples: Telecommunication systems, control systems, altitude, and flight control systems in aerospace applications, audio/video recording, and play-back (compact-disk/MP3 players, video cameras…etc.), high-performance hard-disk drives, modems, video boards, noise cancellation systems, … etc.
Manufacturers and models: Texas Instruments TMS320C6000, TMS320C5000, Motorola 56000, 96000, Analog devices ADSP2100, ADSP21000, ... etc.
Typical features
• Fixed-point processor (TMS320C5000, 56000...) or floating point processor
(TMS320C67, 96000...)
• Architecture optimized for intensive computation. For instance the TMS320C67 can
do 1000 Million floating point operations a second (1 GIGA Flop).
• Narrow address bus supporting a only limited amounts of memory.
• Specialized addressing modes to efficiently support signal processing operations
(circular addressing for filters, bit-reverse addressing for Fast Fourier
Transforms…etc.)
• Narrow data formats (16 bits or 32 bits typical).
• Many specialized peripherals integrated on the chip (serial ports, memory,
timers…etc.)
• Low power consumption.
• Low cost.
1.2 Binary Numbers
A decimal number such as 7392 represents a quantity equal to 7 thousands plus 3 hundreds, plus 9 tens, plus 2 units. The thousands, hundreds, etc. are powers of 10 implied by the position of the coefficients. To be more exact, 7392 should be written as
7 ´ 103 + 3 ´ 102 + 9 ´ 101 + 2 ´ 100
However, the convention is to write only the coefficients and from their position deduce the necessary powers of 10. In general, a number with a decimal point is represented by a series of coefficients as follows:
a5 a4 a3 a2 al a0 . a-1 a-2 a-3
The aj coefficients are one of the ten digits (0, 1, 2, … , 9), and the subscript value j gives the place value and, hence, the power of 10 by which the coefficient must be multiplied.
105a5 + 104a4 + 103a3 + l02a2 + l01a1 + l00a0 + 10-1a-1 + 10-2a-2 + 10-3a-3
The decimal number system is said to be of base, or radix, 10 because it uses ten digits and the coefficients are multiplied by powers of 10. In the binary system, the coefficients of the binary numbers system have two possible values: 0 and 1. Each coefficient a, is multiplied by 2’. For example, the decimal equivalent of the binary number 11010.11 is 26.75, as shown from the multiplication of the coefficients by powers of 2:
1 ´ 24 + 1 ´ 23 + 0 ´ 22 + 1 ´ 21 + 0 ´ 20 + 1 ´ 2-1 + 1 ´ 2-2 = 26.75
In general, a number expressed in base-r system has coefficients multiplied by powers of r:
an . rn + an-1 . rn-1 + … + a2 . r2 + a1 . r + a0 + a-1 . r-1 + a-2 . r-2 + … + a-m . r-m
The coefficients aj range in value from 0 to r-1. To distinguish between numbers of different bases, we enclose the coefficients in parentheses and write a subscript equal to the base used (except sometimes for decimal numbers, where the content makes it obvious that it is decimal).
1.2.1 Arithmetic Operations
Arithmetic operations with numbers in base r follow the same rules as for decimal numbers. When other than the familiar base 10 is used, one must be careful to use only the r allowable digits. Examples of addition, subtraction, and multiplication of two binary numbers are as follows:
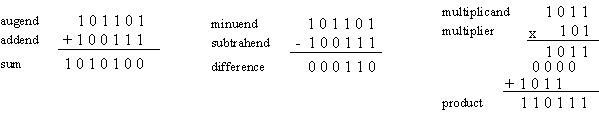
Figure 1‑1: Binary arithmetic operations.
The sum of two binary numbers is calculated by the same rules as in decimal, except that the digits of the sum in any significant position can be only 0 or 1. Any carry obtained in a given significant position is used by the pair of digits one significant position higher. The subtraction is slightly more complicated. The rules are still the same as in decimal, except that the borrow in a given significant position adds 2 to a minuend digit. (A borrow in the decimal system adds 10 to a minuend digit.) Multiplication is very simple. The multiplier digits are always 1 or 0. Therefore, the partial products are equal either to the multiplicand or to 0.
1.2.2 Complements
Complements are used in digital computers for simplifying the subtraction operation and for logical manipulation. There are two types of complements for each base-r system: the radix complement and the diminished radix complement. The first is referred to as the r’s complement and the second as the (r-1)‘s complement. When the value of the base r is substituted in the name, the two types are referred to as the 2’s complement and 1’s complement for binary numbers, and the 10’s complement and 9’s complement for decimal numbers.
1.2.2.1 Diminished Radix Complement
Given a number N in base r having n digits, the (r-l)’s complement of N is defined as:
![]()
For decimal numbers, r = 10 and r-1 = 9, so the 9’s complement of N is (10n-1)-N. Now, 10n represents a number that consists of a single 1 followed by n 0’s. 10n-1 is a number represented by n 9’s. For example, if n = 4, we have l04 = 10,000 and l04-1 = 9999. It follows that the 9’s complement of a decimal number is obtained by subtracting each digit from 9. Some numerical examples follow.
The 9’s complement of 546700 is 999999 - 546700 = 453299.
The 9’s complement of 012398 is 999999 – 012398 = 987601.
For binary numbers, r = 2 and r-1 = 1, so the l’s complement of N is (2n-1)-N. Again. 2n is represented by a binary number that consists of a 1 followed by n 0’s. 2 n-1 is a binary number represented by n 1‘s. For example, if n = 4, we have 2 4 = (10000)2 and 24-1 = (1111)2. Thus, the l’s complement of a binary number is obtained by subtracting each digit from 1. However, when subtracting binary digits from 1. we can have either 1-0 = 1 or 1-1=0, which causes the bit to change from 0 to 1 or from 1 to 0. Therefore, the l’s complement of a binary number is formed by changing l’s to 0’s and 0’s to l’s. The following are some numerical examples.
The l’s complement of 1011000 is 0100111.
The l’s complement of 0101101 is 1010010.
1.2.2.2 Radix Complement
The r’s complement of an n-digit number N in base r is defined as rn-N for N ¹ 0 and 0 for N=0. Comparing with the (r-1)’s complement, we note that the r’ s complement is obtained by adding 1 to the (r-1)’s complement since rn-N = [(rn-1)-N ] + 1. Thus, the 10’s complement of decimal 2389 is 7610 + 1=7611 and is obtained by adding 1 to the 9’s-complement value. The 2’s complement of binary 101100 is 010011 + 1 = 010100 and is obtained by adding 1 to the 1’s-complement value.
Since 10n is a number represented by a 1 followed by n 0’s, l0n-N, which is the 10’s complement of N, can be formed also by leaving all least significant 0’s unchanged, subtracting the first nonzero least significant digit from 10, and subtracting all higher significant digits from 9.
The 10’s complement of 012398 is 987602.
The 10’s complement of 246700 is 753300.
The 10’s complement of the first number is obtained by subtracting 8 from 10 in the least significant position and subtracting all other digits from 9. The 10’s complement of the second number is obtained by leaving the two least significant 0’s unchanged, subtracting 7 from 10. and subtracting the other three digits from 9.
Similarly, the 2’s complement can be formed by leaving all least significant 0’s and the first 1 unchanged, and replacing l’s with 0’s and 0’s with l’s in all other higher significant digits.
The 2’s complement of 1101100 is 0010100.
The 2’s complement of 0110111 is 1001001.
The 2’s complement of the first number is obtained by leaving the two least significant 0’s and the first 1 unchanged, and then replacing l’s with 0’s and 0’s with l’s in the other four most-significant digits. The 2’s complement of the second number is obtained by leaving the least significant 1 unchanged and complementing all other digits.
In the previous definitions, it was assumed that the numbers do not have a radix point. If the original number N contains a radix point, the point should be removed temporarily in order to form the r’s or (r-l)’s complement. The radix point is then restored to the complemented number in the same relative position. It is also worth mentioning that the complement of the complement restores the number to its original value. The r’s complement of N is rn-N. The complement of the complement is r-(rn-N)=N, giving back the original number.
1.2.2.3 Subtraction with Complements
The direct method of subtraction taught in elementary schools uses the borrow concept. In this method, we borrow a 1 from a higher significant position when the minuend digit is smaller than the subtrahend digit. This seems to be easiest when people perform subtraction with paper and pencil. When subtraction is implemented with digital hardware, this method is found to be less efficient than the method that uses complements.
The subtraction of two n-digit unsigned numbers M-N in base r can be done as follows:
1. Add the minuend M to the r’s complement of the subtrahend N. This performs M + (rn- N) = M - N + rn.
2. If M ³ N, the sum will produce an end carry, rn, which is discarded; what is left is the result M-N.
3. If M < N, the sum does not produce an end carry and is equal to rn-(N – M), which is the r’s complement of (N - M). To obtain the answer in a familiar form, take the r’s complement of the sum and place a negative sign in front.
The following examples illustrate the procedure.
Example: Using 10’s complement, subtract 72532 - 3250.
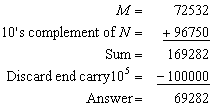
Note that M has 5 digits and N has only 4 digits. Both numbers must have the same number of digits; so we can write N as 03250. Taking the 10’s complement of N produces a 9 in the most significant position. The occurrence of the end carry signifies that M - N and the result is positive.
Example: Using 10’s complement, subtract 3250 – 72532.
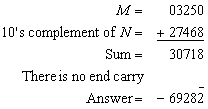
Note that since 3250 < 72532, the result is negative. Since we are dealing with unsigned numbers, there is really no way to get an unsigned result for this case. When subtracting with complements, the negative answer is recognized from the absence of the end carry and the complemented result. When working with paper and pencil, we can change the answer to a signed negative number in order to put it in a familiar form. Subtraction with complements is done with binary numbers in a similar manner using the same procedure outlined before.
1.2.3 Signed Binary Numbers
Positive integers including zero can be represented as unsigned numbers. However, to represent negative integers, we need a notation for negative values. In ordinary arithmetic, a negative number is indicated by a minus sign and a positive number by a plus sign. Because of hardware limitations, computers must represent everything with binary digits, commonly referred to as bits. It is customary to represent the sign with a bit placed in the leftmost position of the number. The convention is to make the sign bit 0 for positive and 1 for negative.
It is important to realize that both signed and unsigned binary numbers consist of a string of bits when represented in a computer. The user determines whether the number is signed or unsigned. If the binary number is signed, then the leftmost bit represents the sign and the rest of the hits represent the number. If the binary number is assumed to be unsigned, then the leftmost bit is the most significant bit of the number. For example, the string of bits 01001 can be considered as 9 (unsigned binary) or a +9 (signed binary) because the leftmost bit is 0. The string of bits 11001 represent the binary equivalent of 25 when considered as an unsigned number or as -9 when considered as a signed number because of the 1 in the leftmost position, which designates negative, and the other four bits, which represent binary 9. Usually, there is no confusion in identifying the bits if the type of representation for the number is known in advance.
The representation of the signed numbers in the last example is referred to as the signed-magnitude convention. In this notation, the number consists of a magnitude and a symbol (+ or -) or a bit (0 or 1) indicating the sign. This is the representation of signed numbers used in ordinary arithmetic. When arithmetic operations are implemented in a computer, it is more convenient to use a different system for representing negative numbers, referred to as the signed-complement system. In this system, a negative number is indicated by its complement. Whereas the signed-magnitude system negates a number by changing its sign, the signed-complement system negates a number by taking its complement. Since positive numbers always start with 0 (plus) in the leftmost position, the complement will always start with a 1, indicating a negative number. The signed-complement system can use either the 1’s or the 2’s complement, but the 2’s complement is the most common.
As an example, consider the number 9 represented in binary with eight bits. +9 is represented with a sign bit of 0 in the leftmost position followed by the binary equivalent of 9 to give 00001001. Note that all eight bits must have a value and, therefore, 0’s are inserted following the sign bit up to the first 1. Although there is only one way to represent +9, there are three different ways to represent -9 with eight bits:
In
signed-magnitude
representation
: 10001001
In signed-1’s-complement
representation
: 11110110
In signed-2’s-complement representation
: 11110111
In signed-magnitude, -9 is obtained from +9 by changing the sign bit in the leftmost position from 0 to 1. In signed-1’s complement, -9 is obtained by complementing all the bits of +9, including the sign bit. The signed-2’s-complement representation of –9 is obtained by taking the 2’s complement of the positive number, including the sign bit.
The signed-magnitude system is used in ordinary arithmetic, but is awkward when employed in computer arithmetic. Therefore, the signed-complement is normally used. The l’s complement imposes some difficulties and is seldom used for arithmetic operations except in some older computers. The 1’s complement is useful as a logical operation since the change of 1 to 0 or 0 to I is equivalent to a logical complement operation, as will be shown in the next chapter. The following discussion of signed binary arithmetic deals exclusively with the signed-2’s-complement representation of negative numbers. The same procedures can be applied to the signed-i ‘s-complement system by including the end-around carry as done with unsigned numbers.
1.2.4 Arithmetic Addition
The addition of two numbers in the signed-magnitude system follows the rules of ordinary arithmetic. If the signs are the same, we add the two magnitudes and give the sum the common sign. If the signs are different, we subtract the smaller magnitude from the larger and give the result the sign of the larger magnitude. For example, (+25) + (-37)=-(37-25) = -12 and is done by subtracting the smaller magnitude 25 from the larger magnitude 37 and using the sign of 37 for the sign of the result. This is a process that requires the comparison of the signs and the magnitudes and then performing either addition or subtraction. The same procedure applies to binary numbers in signed-magnitude representation. In contrast, the rule for adding numbers in the signed-complement system does not require a comparison or subtraction, but only addition. The procedure is very simple and can be stated as follows for binary numbers.
The addition of two signed binary numbers with negative numbers represented in signed-2’s-complement form is obtained from the addition of the two numbers, including their sign bits. A carry out of the sign-bit position is discarded. Numerical examples for addition follow. Note that negative numbers must be initially in 2’s complement and that the sum obtained after the addition if negative is in 2’s-complement form.




In each of the four cases, the operation performed is addition with the sign bit included. Any carry out of the sign-bit position is discarded, and negative results are automatically in 2’s-complement form.
In order to obtain a correct answer, we must ensure that the result has a sufficient number of bits to accommodate the sum. If we start with two n-bit numbers and the sum occupies n+1 bits, we say that an overflow occurs. When one performs the addition with paper and pencil, an overflow is not a problem since we are not limited by the width of the page. We just add another 0 to a positive number and another 1 to a negative number in the most-significant position to extend them to n + 1 bits and then perform the addition. Overflow is a problem in computers because the number of bits that hold a number is finite, and a result that exceeds the finite value by 1 cannot be accommodated.
The complement form of representing negative numbers is unfamiliar to those used to the signed-magnitude system. To determine the value of a negative number when in signed-2’s complement. it is necessary to convert it to a positive number to place it in a more familiar form. For example, the signed binary number 11111001 is negative because the leftmost bit is 1. Its 2’s complement is 00000111, which is the binary equivalent of +7. We therefore recognize the original negative number to be equal to -7.
1.2.5 Arithmetic Subtraction
Subtraction of two signed binary numbers when negative numbers are in 2’s-complement form is very simple and can be stated as follows: Take the 2’s complement of the subtrahend (including the sign bit) and add-it to the minuend (including the sign bit). A carry out of the sign-bit position is discarded. This procedure occurs because a subtraction operation can be changed to an addition operation if the sign of the subtrahend is changed. This is demonstrated by the following relationship:
(± A)-(+ B) = (± A) + (-B)
(± A)-(- B) = (± A) + (+B)
But changing a positive number to a negative number is easily done by taking its 2’s complement. The reverse is also true because the complement of a negative number in complement form produces the equivalent positive number. Consider the subtraction of (-6) - (-13) = + 7. In binary with eight bits, this is written as (11111010-11110011). The subtraction is changed to addition by taking the 2’s complement of the subtrahend (-13) to give (+13). In binary, this is 11111010 + 00001101 = 100000111. Removing the end carry, we obtain the correct answer 00000111 (+7).
It is worth noting that binary numbers in the signed-complement system are added and subtracted by the same basic addition and subtraction rules as unsigned numbers. Therefore, computers need only one common hardware circuit to handle both types of arithmetic. The user or programmer must interpret the results of such addition or subtraction differently, depending on whether it is assumed that the numbers are signed or unsigned.
1.2.6 Binary Multiplication
Binary multiplication is carried out in very much the same manner as decimal multiplication, obtaining partial products in the conventional manner, but adding the latter in binary fashion. That is, write down the multiplier and the multiplicand, multiply entire multiplicand by each multiplier digit in turn, and add the partial results. In binary multiplication, 0 × 0 = 0, 0 × 1 = 0, 1 × 0 = 0, and 1 × 1 = 1. Example, multiply 10111 (binary 23) by 11001 (binary 25):

Since computers cannot handle blanks, trailing zeros should be filled in where necessary. Note that, every digit in a binary number is either 1 or 0, so every step in multiplication requires either adding or not adding. This process requires the ability to add, and shift left. In a left shift, digits migrate left, most significant bit is lost, least significant bit is set to 0. Multiplication is a repeated addition. Regarding to the multiplication of negative numbers, since addition of negative twos complement numbers works, so multiplication works too.
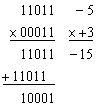
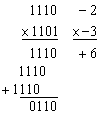
1.2.7 Binary Division
Binary division is carried out in a manner similar to decimal division, operates symmetrically to multiplication, the difference being that one subtracts instead of adds and shifts right to divide by 2 instead of multiplying by 2, , as the following example will show: Divide 1001 (binary 9) by 0100 (binary 4)
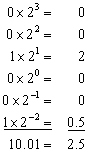
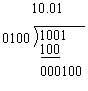
If we assume a fixed length register of and 2’s complement number representation and the divisor and dividend are both assumed to be positive integers, after initialization, first step will be the normalization operation which is: shift the divisor to the left until the leftmost 1 is just to the right of the sign bit while counting the number of shifts. For example:
01101101 dividend (109)
00010101 divisor (21)
00101010 first shift
01010100 second shift
The next step will subtraction and shifting loop. Note that if the subtraction is positive, the quotient has a 1 in the current bit position. The quotient string is built incrementally by adding the result for the current but position to the end of the quotient, and shifting left.
1.2.8 Fixed Point (Integers)
Fixed-point representation is used to store integers, the positive and negative whole numbers. In the simplest case, the 216=65,536 possible bit patterns are assigned to the numbers 0 through 65,535. This is called unsigned integer format, and a simplified example is shown in Figure 1‑2 (using only 4 bits per number). Conversion between the bit pattern and the number being represented is nothing more than changing between base 2 (binary) and base 10 (decimal). The disadvantage of unsigned integer is that negative numbers cannot be represented.
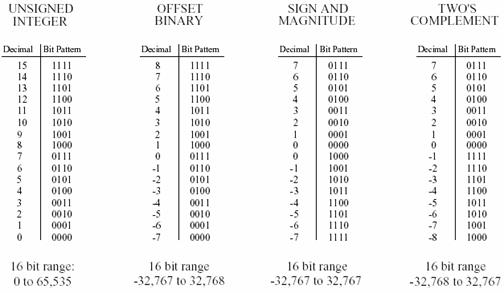
Figure 1‑2: Fixed point binary representations.
Offset binary is similar to unsigned integer, except the decimal values are shifted to allow for negative numbers. In the 4 bit example of Figure 1‑2, the decimal numbers are offset by seven, resulting in the 16 bit patterns corresponding to the integer numbers -7 through 8. In this same manner, a 16 bit representation would use 32,767 as an offset, resulting in a range between -32,767 and 32,768. Offset binary is not a standardized format, and you will find other offsets used, such 32,768. The most important use of offset binary is in ADC and DAC. For example, the input voltage range of -5v to 5v might be mapped to the digital numbers 0 to 4095, for a 12 bit conversion.
Sign and magnitude is another simple way of representing negative integers. The far left bit is called the sign bit, and is made a zero for positive numbers, and a one for negative numbers. The other bits are a standard binary representation of the absolute value of the number. This results in one wasted bit pattern, since there are two representations for zero, 0000 (positive zero) and 1000 (negative zero). This encoding scheme results in 16 bit numbers having a range of -32,767 to 32,767.
These first three representations are conceptually simple, but difficult to implement in hardware. Remember, when A=B+C is entered into a computer program, some hardware engineer had to figure out how to make the bit pattern representing B, combine with the bit pattern representing C, to form the bit pattern representing A. Two's complement is the format loved by hardware engineers, and is how integers are usually represented in computers. To understand the encoding pattern, look first at decimal number zero in Figure 1‑2, which corresponds to a binary zero, 0000. As we count upward, the decimal number is simply the binary equivalent (0 = 0000, 1 = 0001, 2 = 0010, 3 = 0011, etc.). If we again start at 0000 and begin subtracting, the digital hardware automatically counts in two's complement: 0 = 0000, -1 = 1111, -2 = 1110, -3 = 1101, etc. This is analogous to the odometer in a new automobile. If driven forward, it changes: 00000, 00001, 00002, 00003, and so on. When driven backwards, the odometer changes: 00000, 99999, 99998, 99997, etc.
Using 16 bits, two's complement can represent numbers from -32,768 to 32,767. The left most bit is a 0 if the number is positive or zero, and a 1 if the number is negative. Consequently, the left most bit is called the sign bit, just as in sign and magnitude representation. Converting between decimal and two's complement is straightforward for positive numbers, a simple decimal to binary conversion. For negative numbers, the following algorithm is often used: take the absolute value of the decimal number, convert it to binary, and complement all of the bits (ones become zeros and zeros become ones), add 1 to the binary number. Two's complement is hard for humans, but easy for digital electronics.
1.2.9 Real Numbers - Floating Point
The usual method used by computers to represent real numbers is floating point notation. The encoding scheme for floating point numbers is more complicated than for fixed point. There are many varieties of floating point notation and each has individual characteristics. The key concept is that, a real number is represented by a number called a mantissa, times a base raised to an integer power, called an exponent. The base is usually fixed, and the mantissa and exponent vary to represent different real numbers. For example, the number 387.53 could be represented as 38753×10-2. The mantissa is 38753, and the exponent is –2. Other possible representations are 0.38753×103 and 387.53×100. We choose the representation in which the mantissa is an integer with no trailing 0s.
Floating point representation is similar to scientific notation, except everything is carried out in base two, rather than base ten. While several similar formats are in use, the most common is ANSI/IEEE Std. 754-1985. This standard defines the format for 32 bit numbers called single precision, as well as 64 bit numbers called double precision. As shown in Figure 1‑3, the 32 bits used in single precision are divided into three separate groups: bits 0 through 22 form the mantissa, bits 23 through 30 form the exponent, and bit 31 is the sign bit.

Figure 1‑3: Single precision floating point bit pattern.
These bits form the floating-point number, v, by the following relation:
![]()
where S is the value of the sign bit, M is the value of the mantissa, and E is the value of the mantissa. The term (-1)S, simply means that the sign bit, S, is 0 for a positive number and 1 for a negative number. The variable, E, is the number between 0 and 255 represented by the eight exponent bits. Subtracting 127 from this number allows the exponent term to run from 2-127 to 2128. In other words, exponent is stored in offset binary with an offset of 127. The mantissa, M, is formed from the 23 bits as a binary fraction. For example, the decimal fraction: 2.783, is interpreted: 2 + 7/10 + 8/100 + 3/1000. The binary fraction: 1.0101 means: 1 + 0/2 + 1/4 + 0/8 + 1/16. Floating point numbers are normalized in the same way as scientific notation, that is, there is only one nonzero digit left of the decimal point (called a binary point in base 2). Since the only nonzero number that exists in base two is 1, the leading digit in the mantissa will always be a 1, and therefore does not need to be stored. Removing this redundancy allows the number to have an additional one bit of precision. The 23 stored bits, referred to by the notation: m22 m21 m20 … m0, form the mantissa according to:
![]()
In other words, M = 1 + m222-1 + m212-2+ m202-3…. If bits 0 through 22 are all zeros, M takes on the value of one. If bits 0 through 22 are all ones, M is just a hair under two, i.e., 2-2-23.
Using this encoding scheme, the largest number that can be represented is: ±(2-2-23)×2128 = ± 6.8 × 1038. Likewise, the smallest number that can be represented is: ± 1.0 × 2-127 = ± 5.9 × 10-39. The IEEE standard reduces this range slightly to free bit patterns that are assigned special meanings. In particular, the largest and smallest numbers allowed in the standard are ± 3.4 × 1038 and ± 1.2 × 10-38 respectively. The freed bit patterns allow three, special classes of numbers: ±0 is defined as all of the mantissa and exponent bits being zero. ± 4 is defined as all of the mantissa bits being zero, and all of the exponent bits being one. A group of very small unnormalized numbers between ±1.2×10-38 and ±1.4 × 10-45. These are lower precision numbers obtained by removing the requirement that the leading digit in the mantissa be a one. Besides these three special classes, there are bit patterns that are not assigned a meaning, commonly referred to as NANs (Not A Number).
The IEEE standard for double precision simply adds more bits to both the mantissa and exponent. Of the 64 bits used to store a double precision number, bits 0 through 51 are the mantissa, bits 52 through 62 are the exponent, and bit 63 is the sign bit. As before, the mantissa is between one and just under two. The 11 exponent bits form a number between 0 and 2047, with an offset of 1023, allowing exponents from 2-1023 to 21024. The largest and smallest numbers allowed are ±1.8×10308 and ±2.2×10-308 respectively. These are incredibly large and small numbers! It is quite uncommon to find an application where single precision is not adequate. You will probably never find a case where double precision limits what you want to accomplish.
1.2.10 Number Precision
The errors associated with number representation are very similar to quantization errors during ADC. You want to store a continuous range of values; however, you can represent only a finite number of quantized levels. Every time a new number is generated, after a math calculation for example, it must be rounded to the nearest value that can be stored in the format you are using.
As an example, imagine that you allocate 32 bits to store a number. Since there are exactly different bit patterns possible, you can 232 = 4,294,967,296 represent exactly 4,294,967,296 different numbers. Some programming languages allow a variable called a long integer, stored as 32 bits, fixed point, two's complement. This means that the 4,294,967,296 possible bit patterns represent the integers between -2,147,483,648 and 2,147,483,647. In comparison, single precision floating point spreads these 4,294,967,296 bit patterns over the much larger range: -3.4 × 1038 to 3.4 × 1038.
With fixed-point variables, the gaps between adjacent numbers are always exactly one. In floating point notation, the gaps between adjacent numbers vary over the represented number range. If we randomly pick a floating point number, the gap next to that number is approximately ten million times smaller than the number itself (to be exact, 2-24 to 2-23 times the number). This is a key concept of floating point notation: large numbers have large gaps between them, while small numbers have small gaps. Figure 1‑4 illustrates this by showing consecutive floating-point numbers, and the gaps that separate them.

Figure 1‑4: The gaps between adjacent numbers.